不刷算法题的程序员不是好程序员。然而,LeetCode 上的题目这么多,不可能全部刷完。因此,最好的做法是集中刷高频题目。幸好 codetop 已经帮我们总结了一千道高频题目,我们只需按图索骥即可。
本文将记录我所刷过的题目的解题过程。
无重复字符的最长子串(中等)
https://leetcode.cn/problems/longest-substring-without-repeating-characters/description/
给定一个字符串 s ,请你找出其中不含有重复字符的最长子串的长度。
子字符串 是字符串中连续的 非空 字符序列。


首先,这道题肯定不能用暴力法求解,如果试图在循环中拿到所有子串的情况,将会有 n*(n+1)/2 种结果,而且多层循环的每次迭代我们都需要回放之前遍历过的情况以确保得到的是最长不重复子串,这简直就是灾难:
因此我们需要利用空间换时间,通过一种数据结构提前缓存好已遍历过的子串长度。由于题干限定了字符串中的字符在 ASCII 范围内,且字符串长度不超过 50000,因此我们可以通过长度为 255 的 short 数组 arr 来映射每个字符对应的子串长度。
然后用滑动窗口求解最小不重复子串长度:
- 从输入字符串的第一个元素开始向后遍历,每遍历到一个字符(用
end 表示其索引),将该字符在输入字符串中的索引值 + 1 存到 arr 中与字符 ASCII 码对应的位置中。 - 在字符存入
arr 前,需要先判断当前字符是否已经被 arr 存储过。如果发现某个字符对应的数组元素不为 0,表示遇到了重复字符,因此需要更新不重复子串首地址 start 的位置。且 start 的更新原则是单调不减。start 单调不减是为了解决 “ab - ba” 问题,例如我们已经访问过了字符 a 和 b,此时又遇到了一次 b,则 start 会被更新到第一个 b 身后。紧接着又遇到了一个 a 字符,此时 start 甚至已经跨过了 b,如果往回倒,就会导致第一个重复的 b 元素被漏掉,从而结果错误。
- 然后计算当前不重复子串长度,即
start 到 end 之间的元素个数,并用 maxLen 变量保存结果。更新原则是尽可能选择更大的值。
最佳实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| class Solution {
public int lengthOfLongestSubstring(String s) {
int maxLen = 0, sLen = s.length();
short[] arr = new short[255];
// start 用于缓存当前不重复子串的起始索引
// end 表示当前访问的字符索引
for (int start = 0, end = 0; end < sLen; ++end) {
// 获取当前索引处的字符
char endChar = s.charAt(end);
// 如果当前字符重复
if (arr[endChar] != 0) {
// 更新 start,且 start 单调不减
// 将 start 指针移动到与当前字符重复的字符身后
start = Math.max(start, arr[endChar]);
}
// 然后更新当前元素的索引值
arr[endChar] = (short) (end + 1);
// 更新当前 maxLen
maxLen = Math.max(maxLen, end - start + 1);
}
return maxLen;
}
}
|
提交代码后结果如下:
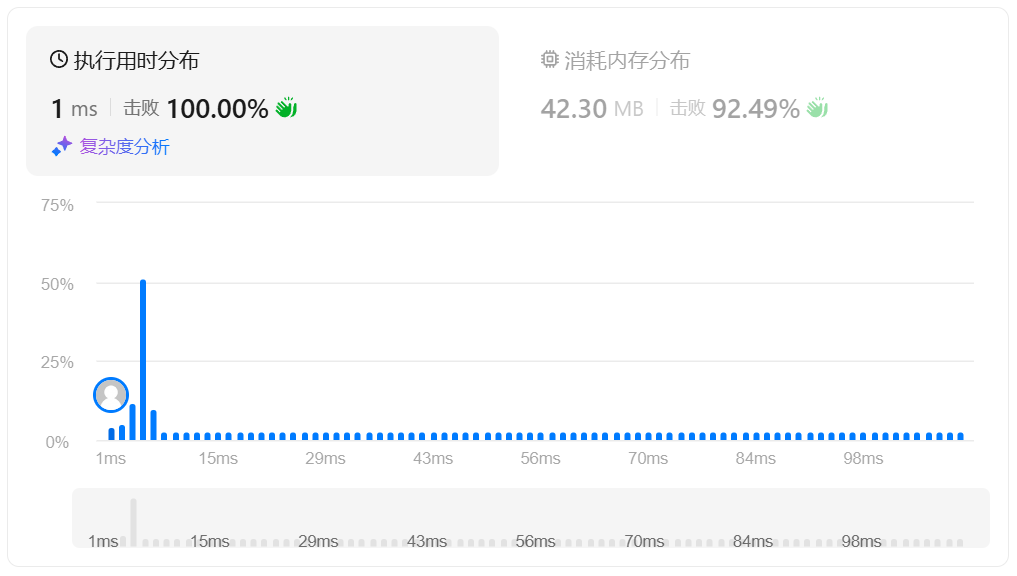
- 时间复杂度:O(N)
- 空间复杂度:O(Min(N,255))
反转链表(容易)
https://leetcode.cn/problems/reverse-linked-list/description/
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
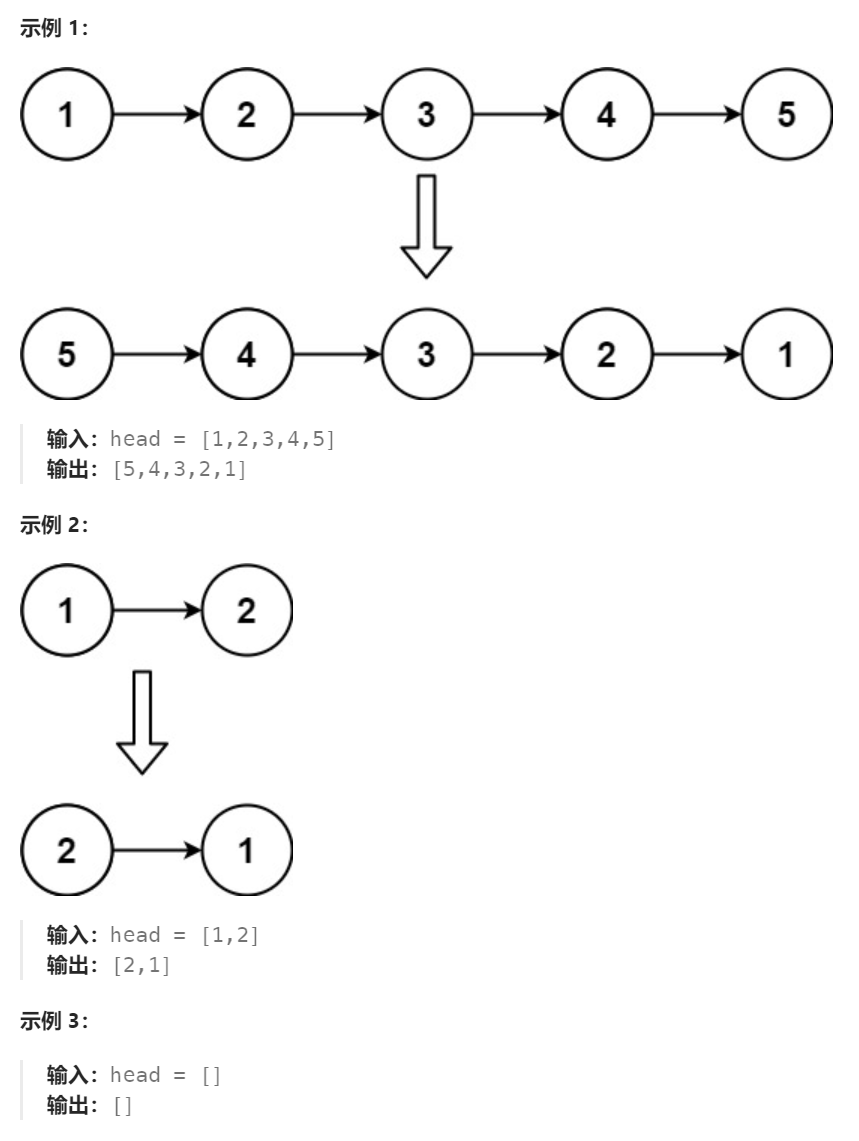

进阶:链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
首先我们用比较容易的迭代法来实现:只需要遍历链表,通过引用暂存节点信息,将其倒着组装形成一个新链表返回即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| /**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
// 特殊情况处理
if (head == null || head.next == null) {
return head;
}
// 先把头结点缓存,作为将来的尾节点
ListNode t = head;
// 然后从第二个节点开始迭代
head = head.next;
// 为节点 next 指空,避免成环
t.next = null;
// 开始遍历
while (head != null) {
// 摘下当前头结点
ListNode tmp = head;
// 头结点后移
head = head.next;
// 将被摘下的头结点指向曾经的前节点
tmp.next = t;
// 更新新链表头
t = tmp;
}
// 返回新链表头
return t;
}
}
|
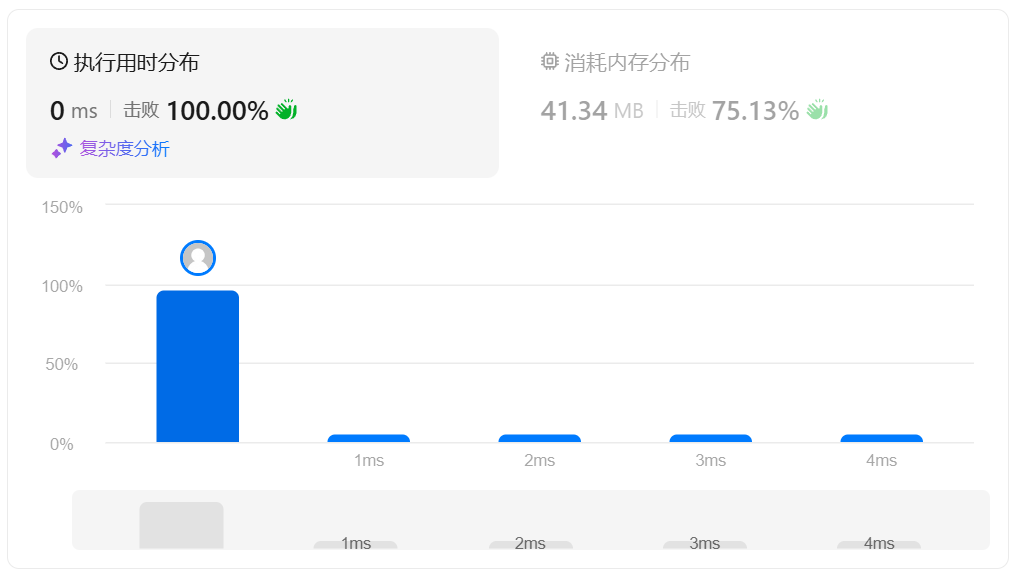
然后我们再考虑通过递归法来实现。递归法难在思想上,只要想通了,代码写起来会非常容易。递归的进入过程顺序与链表一致,退出过程与链表相反,因此我们可以在递归退出的过程中完成新链表的组装:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public ListNode reverseList(ListNode head) {
// 先一路进入,递归到最底层
if (head.next == null) {
return head;
}
// 特殊数据处理
if (head == null) {
return null;
}
// 把最后一个元素返回,作为反转后链表的头结点
ListNode result = reverseList(head.next);
// result 不能动,必须原路返回给最上层,所以只对 head 操作
head.next.next = head;
// 避免成环
head.next = null;
return result;
}
|
LRU 缓存(中等)
https://leetcode.cn/problems/lru-cache/description/
请你设计并实现一个满足 LRU (最近最少使用) 缓存约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。


首先,题目要求 get 和 put 操作的平均时间复杂度必须为 O(1),因此可以选择 HashMap 数据结构。我们可以创建一个内部节点类 Node 表示每个键值对,同时创建一个 Node[] 数组表示哈希表,并通过指针将哈希冲突的数据链接起来。
然后,当数据量超过容量时,需要丢弃不常使用的节点,因此我们可以维护一个双向链表,每次操作一个节点就将其移到链表头,当需要淘汰节点时就将尾部节点移除,这样来实现一个简易的 LRU 队列。
实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
| public class LRUCache {
// 允许的最大容量
private final int capacity;
// 缓存中的键值对数量
private int size;
// 基于链地址实现的哈希表
private final Node[] table;
// 用于淘汰策略
Node head, tail;
/**
* 缓存节点
*/
public static class Node {
final int key;
int value;
// 用于哈希冲突时的链接
Node link;
// 用于 LRU 链接
Node pre, next;
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
public LRUCache(int capacity) {
this.capacity = capacity;
// 将 table 向上取整为 2 的次幂,参考自 HashMap
int n = capacity * 2 - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
n = (n < 0) ? 1 : n + 1;
this.table = new Node[n];
// 创建一个虚拟节点,给 head 与 tail 使用
tail = new Node(-1, -1);
head = tail;
}
public int get(int key) {
int index = Integer.hashCode(key) & (table.length - 1);
// 如果索引位置为空,则返回 -1
if (table[index] == null) {
return -1;
}
// 否则根据 link 指针迭代查找
Node target = table[index];
while (target != null && target.key != key) {
target = target.link;
}
if (target == null) {
return -1; // 没找到
}
// 找到了,更新 LRU
if (target.pre != null) {
target.pre.next = target.next;
}
if (target.next != null) {
target.next.pre = target.pre;
}
// 移动到头部虚节点后方
target.pre = head;
target.next = head.next;
head.next = target;
if (target.next != null) {
target.next.pre = target;
}
// tail 更新
while (tail.next != null) {
tail = tail.next;
}
return target.value;
}
private void resize() {
if (++size > capacity) {
// 首先淘汰掉尾部的一个节点
Node tmp = tail;
tail = tail.pre;
tail.next = null;
tmp.pre = null;
// 然后将被淘汰的节点从哈希桶上摘下
int index = Integer.hashCode(tmp.key) & (table.length - 1);
Node node = table[index];
if (node.key == tmp.key) {
table[index] = node.link;
return;
}
while (node.link != null) {
if (node.link.key == tmp.key) {
node.link = tmp.link;
break;
}
node = node.link;
}
}
}
private void updateLRU(Node node) {
if (head == tail) {
// 初始状态
head.next = node;
node.pre = head;
tail = node;
return;
}
// 如果是已有节点,则先把节点摘下
if (node.pre != null) {
node.pre.next = node.next;
}
if (node.next != null) {
node.next.pre = node.pre;
}
// 然后移到头部虚节点后
node.next = head.next;
if (head.next != null) {
head.next.pre = node;
}
head.next = node;
node.pre = head;
// 更新尾节点
while (tail.next != null) {
tail = tail.next;
}
}
public void put(int key, int value) {
int index = Integer.hashCode(key) & (table.length - 1);
if (table[index] == null) {
// 如果是空位,直接插入
table[index] = new Node(key, value);
// 更新 LRU
updateLRU(table[index]);
// 执行淘汰策略
resize();
return;
}
// 性能优化:如果碰撞的第一个节点恰好是冲突节点,那么直接更新返回
if (table[index].key == key) {
table[index].value = value;
updateLRU(table[index]);
return;
}
// 碰撞后,从哈希桶内寻找空位,或旧值
Node node = table[index];
while (node.link != null && node.link.key != key) {
node = node.link;
}
if (node.link != null) {
// 如果碰撞后,找到了旧值,则更新
node.link.value = value;
updateLRU(table[index]);
return;
}
// 否则插入空位
node.link = new Node(key, value);
// 更新 LRU
updateLRU(node.link);
// 执行淘汰策略
resize();
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
|
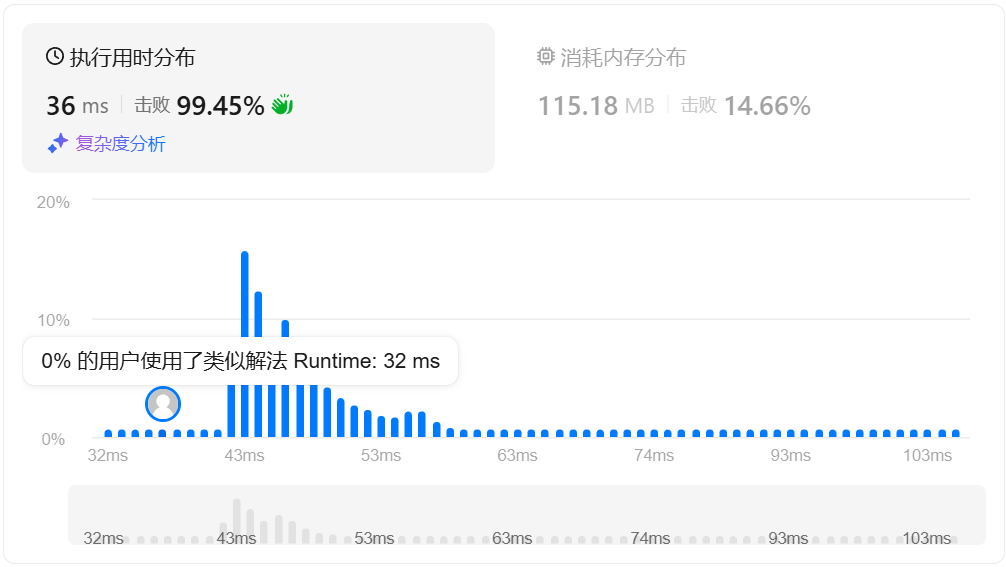
结果如下:
数组中的第 K 个最大元素(中等)
https://leetcode.cn/problems/kth-largest-element-in-an-array/description/
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。


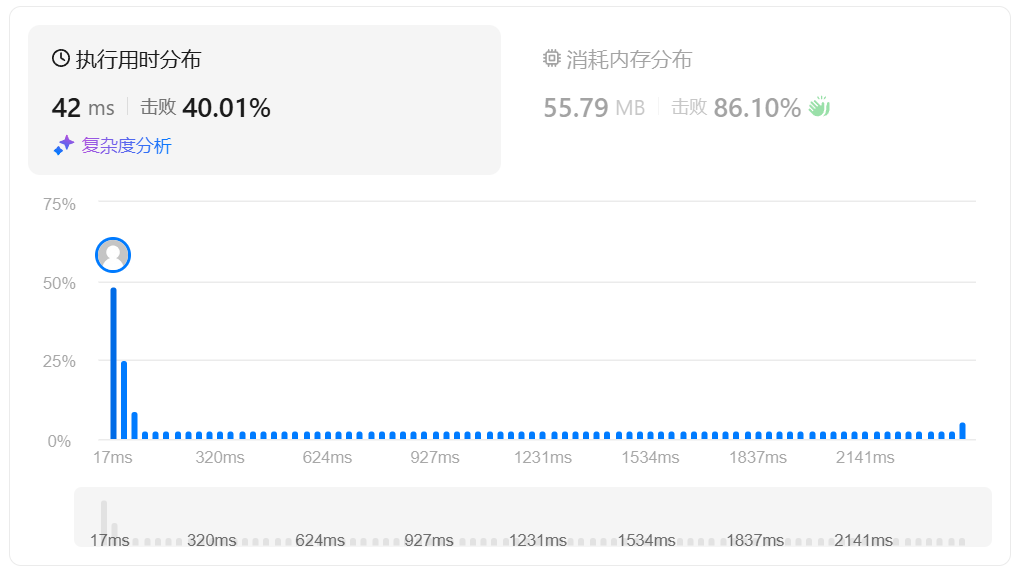
这道题的关键在于时间复杂度要求,一般的排序算法的时间复杂度都在 O(nlogn) 以上,因此不能完全排序后再取结果。为此,我们可以创建一个最大容量为 k 的优先队列,在遍历数组的过程中不断填充优先队列,当容量超过 k 时进行淘汰,以确保队列中始终缓存前 k 大的元素。最终将队列首元素返回,实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class Solution {
public int findKthLargest(int[] nums, int k) {
// 初始化一个优先队列,容量为 k + 1,避免触发扩容
PriorityQueue<Integer> pq = new PriorityQueue<>(k + 1);
int size = 0;
for (int num : nums) {
if (size + 1 > k) {
Integer first = pq.peek();
if (first != null && first <= num) {
pq.poll();
pq.offer(num);
}
} else {
pq.offer(num);
size++;
}
}
Integer result = pq.peek();
return result == null ? -1 : result;
}
}
|
- 最终,该算法的时间复杂度为 O(nlog(k)),比要求略高。不过这是我能力的极限了,真要达到 O(n),可以参考官方解题中的改进版快速排序实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class Solution {
int quickselect(int[] nums, int l, int r, int k) {
if (l == r) return nums[k];
int x = nums[l], i = l - 1, j = r + 1;
while (i < j) {
do i++; while (nums[i] < x);
do j--; while (nums[j] > x);
if (i < j){
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
}
if (k <= j) return quickselect(nums, l, j, k);
else return quickselect(nums, j + 1, r, k);
}
public int findKthLargest(int[] _nums, int k) {
int n = _nums.length;
return quickselect(_nums, 0, n - 1, n - k);
}
}
|
K 个一组翻转链表(困难)
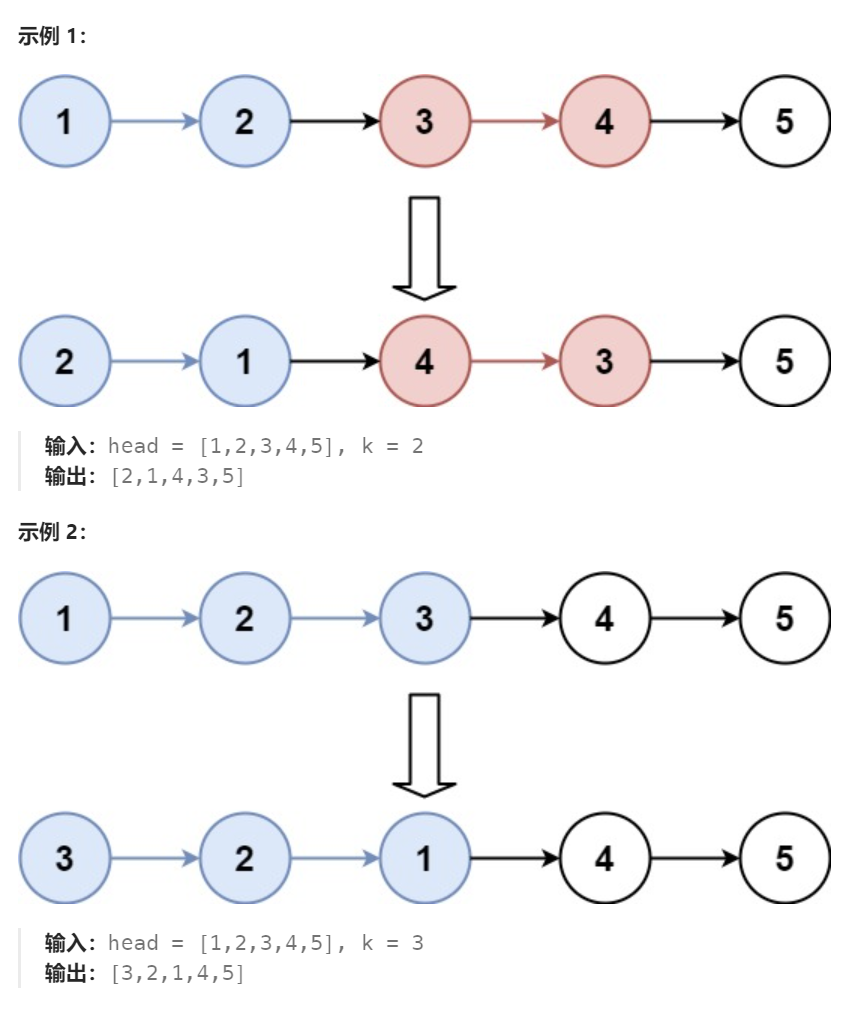
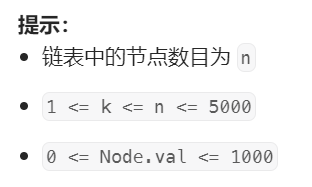
https://leetcode.cn/problems/reverse-nodes-in-k-group/description/
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
进阶:你可以设计一个只用 O(1) 额外内存空间的算法解决此问题吗?
三数之和
https://leetcode.cn/problems/3sum/description/
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。
请你返回所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。


最大子数组和
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组是数组中的一个连续部分。

进阶:如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的 分治法 求解。
手写快速排序
https://leetcode.cn/problems/sort-an-array/description/
给你一个整数数组 nums,请你将该数组升序排列。

合并两个有序链表
https://leetcode.cn/problems/merge-two-sorted-lists/description/
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
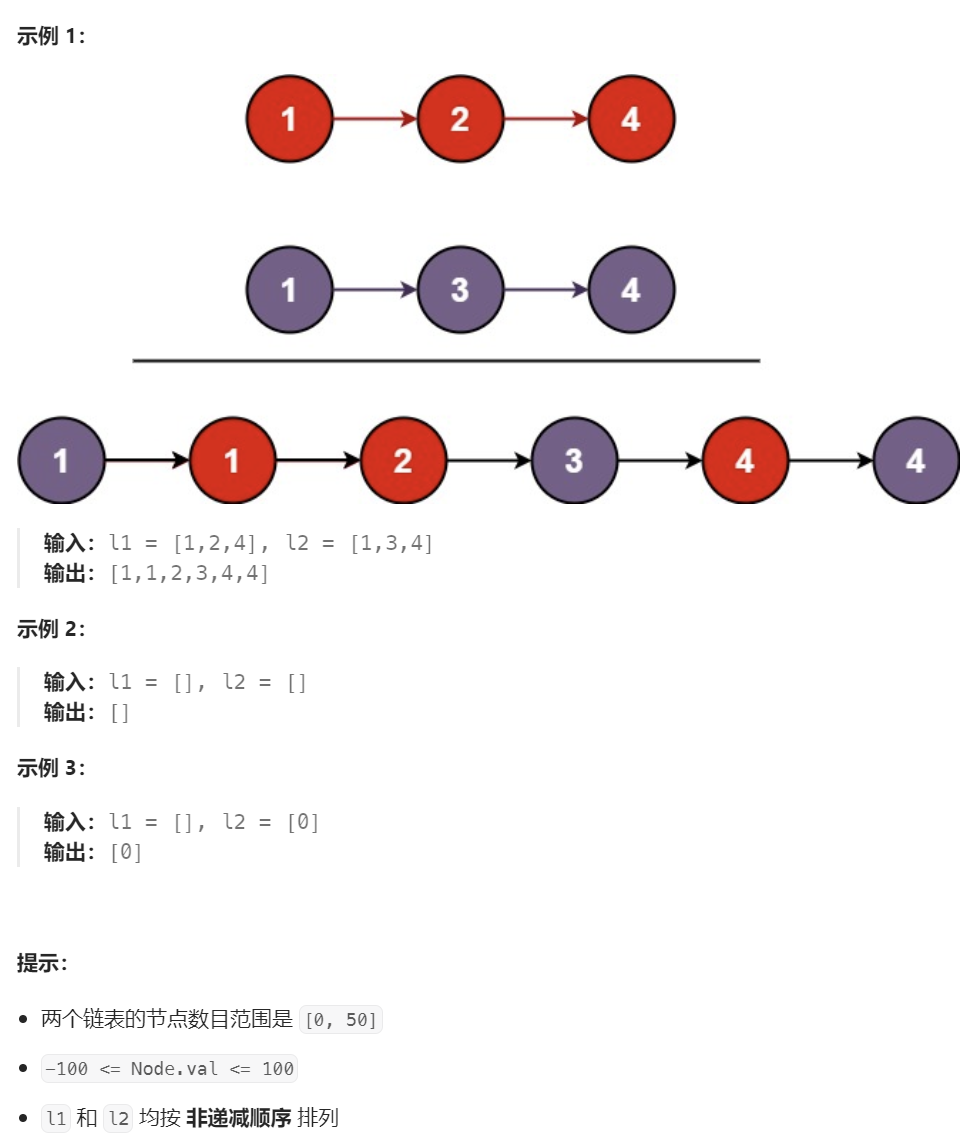
两数之和
https://leetcode.cn/problems/two-sum/
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。

进阶:时间复杂度小于 O(n2) 。