为了适应自己的应用场景,Linux 内核采用了一种名为 slab/slub 的内存管理机制。该机制通过以下四个步骤对物理内存条进行管理,以供内核申请和分配内核对象。具体过程如下:

NUMA 架构
现代服务器通常会配置多个 CPU,因此无法像多核单 CPU 那样通过共享总线访问内存。常见的解决方案是采用 NUMA 架构。在 NUMA 架构中,每个 CPU 有都自己的本地内存和内存控制器,在访问本地节点时,可以直接访问本地内存,从而提升性能。
通过执行 dmidecode 命令,可以查看主板上插着的 CPU 的详细信息:
1
2
3
4
5
6
7
8
9
10
11
12
| Processor Information #第一颗 CPU
Socket Designation: CPU 0
Version: Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz
Core Count: 12
Thread Count: 24
# 省略 ...
Processor Information #第二颗 CPU
Socket Designation: CPU 1
Version: Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz
Core Count: 12
Thread Count: 24
# 省略 ...
|
并且可以显示内存条的相关信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| # CPU0 上总共插着两条内存
Memory Device
Size: 16384 MB
Locator: CPU0 DIMM A1
# 省略 ...
Memory Device
Size: 16384 MB
Locator: CPU0 DIMM A2
# 省略 ...
# CPU1 上总共插着两条内存
Memory Device
Size: 16384 MB
Locator: CPU1 DIMM A1
# 省略 ...
Memory Device
Size: 16384 MB
Locator: CPU1 DIMM A2
# 省略 ...
|
Node 划分
每个 CPU 和它直接连接的内存条组成一个节点 (node):
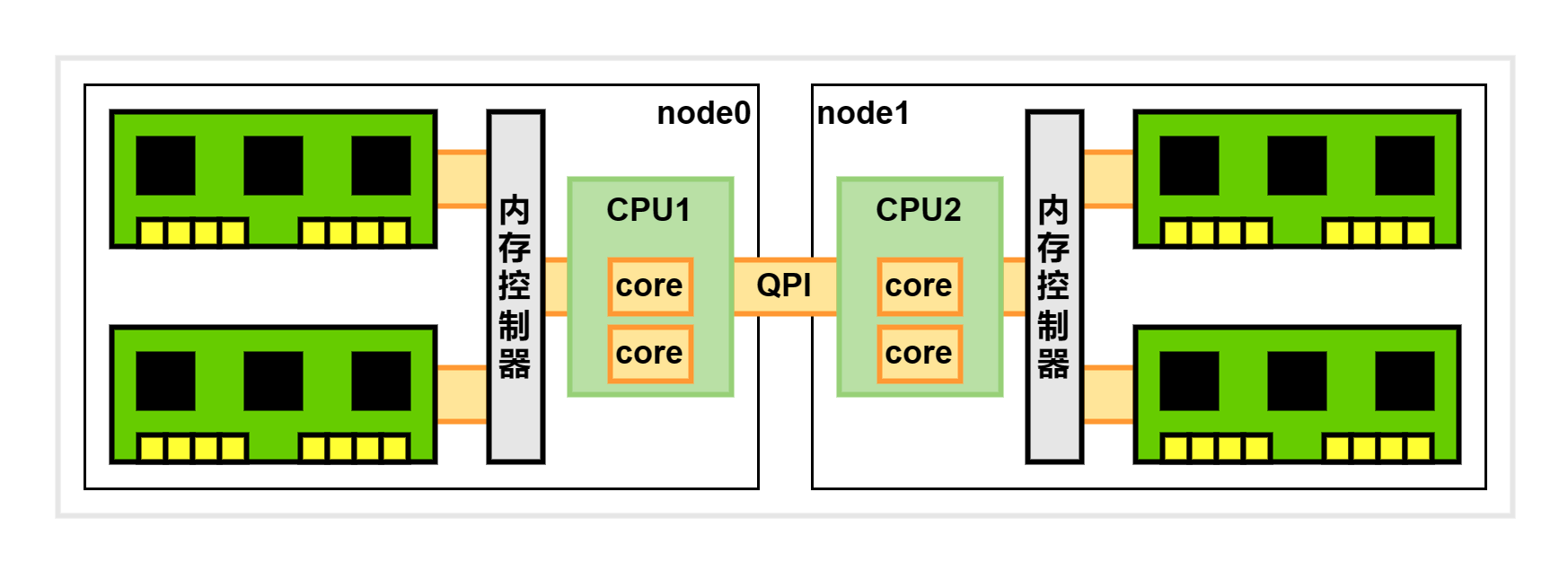
我们可以在终端使用 numactl --hardware 命令看到每个 node 的情况:
1
2
3
4
5
6
7
| available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35
node 0 size: 65419 MB
# 省略 ...
node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46 47
node 1 size: 65419 MB
# 省略 ...
|
Zone 划分
每个 node 又会划分为若干个 zone (区域),zone 表示内存中的一块范围,如下图所示:
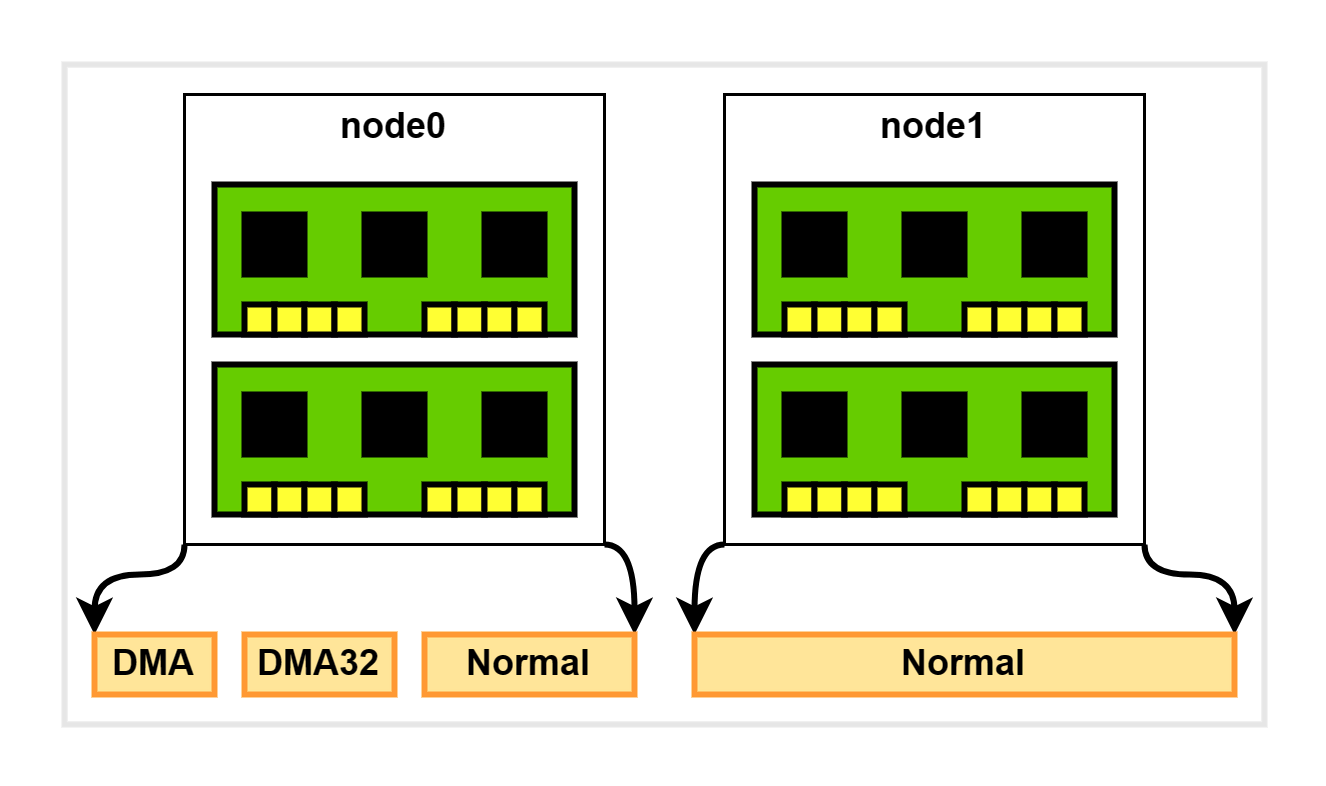
- ZONE_DMA:地址段最低的一块内存区域,供 I/O 设备 DMA 访问。
- ZONE_DMA32:该 zone 用于仅支持 32 位地址总线的 DMA 设备,只在 64 位系统里才有效。
- ZONE_NORMAL:在 x86-64 架构下,DMA 和 DMA32 之外的内存全部在 NORMAL 的 zone 里管理。
扩展:ZONE_HIGHMEM 高端内存
ZONE_HIGHMEM(高端内存)是指 32 位 Linux 内核管理的高地址内存区域。在 32 位系统中,由于地址空间的限制,内核只能映射一部分物理内存,通常为 1GB 左右。当系统中的物理内存超过这个限制时,就需要使用高端内存来管理。高端内存的地址空间不直接映射到内核空间,而是通过页表和临时映射的方式访问,这样可以解决内核地址空间不足的问题。在 Linux 中,高端内存通常被用于存储大型数据结构,例如缓存和文件系统中的数据。
不过,在现今普遍使用 64 位服务器的时代,ZONE_HIGHMEM 已经不再使用了,因为 64 位系统可以直接映射更大的内存,不再受到 32 位系统的限制。
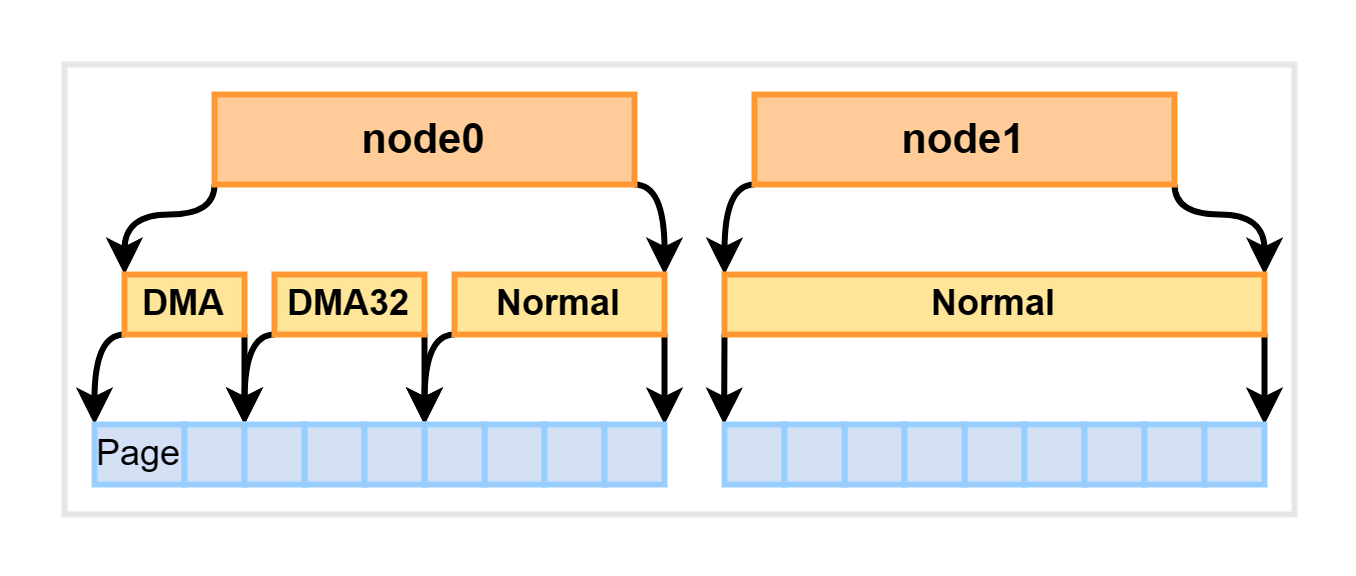
在 Linux 内核中,每个内存管理区域 (zone) 下都包含了许多个页面 (Page),一般每个页面的大小为 4KB。我们可以通过 Linux 中的 proc 文件系统中的 zoneinfo 文件来查看系统中内存区域的划分,以及每个区域所管理的页面数量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| # cat /proc/zoneinfo
Node 0, zone DMA
# 省略 ...
pages free 3808
managed 3840
# 省略 ...
Node 0, zone DMA32
# 省略 ...
pages free 380380
managed 427659
# 省略 ...
Node 0, zone Normal
pages free 15031616
managed 16345717
# 省略 ...
Node 1, zone Normal
pages free 15912823
managed 16777216
# 省略 ...
|
每个页面的大小为 4KB,因此我们可以很容易地计算出每个内存管理区域(zone)的大小。例如,对于上文提到的 node1 中的 Normal 区域,其大小为 16777216 x 4KB = 64GB。
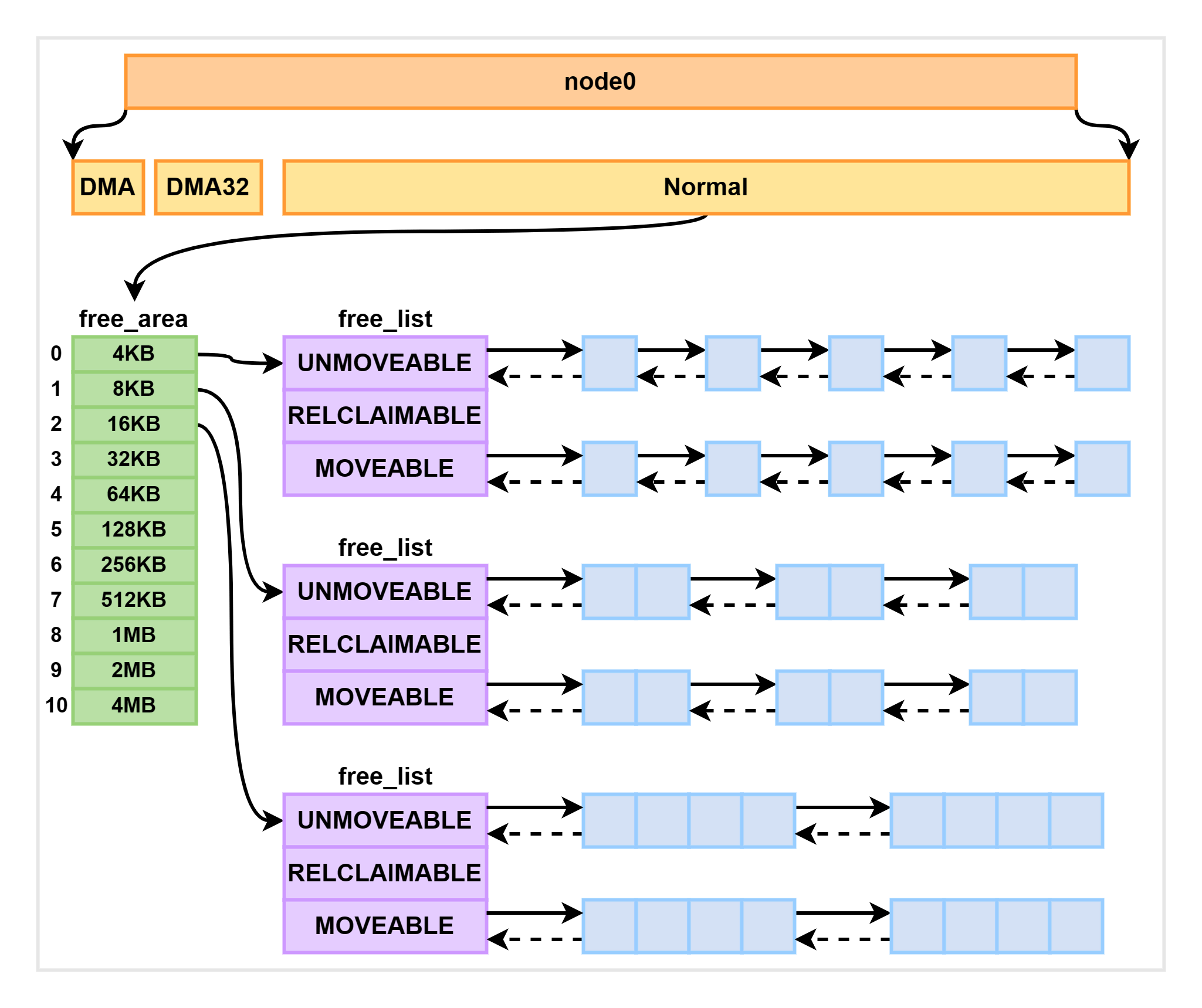
伙伴算法管理空闲页面
每个内存管理区域 (zone) 下都包含大量的页面,Linux 使用伙伴系统对这些页面进行高效的管理。在内核中,表示内存区域的数据结构是 struct zone。该数据结构下的一个数组,即 free_area,管理了绝大部分可用的空闲页面。这个数组是伙伴系统实现的重要数据结构:
1
2
3
4
5
6
| //file: include/linux/mmzone.h
#define MAX_ORDER 11
struct zone {
free_area free_area[MAX_ORDER];
...
}
|
free_area 是一个包含 11 个元素的数组,每个数组元素分别代表可分配连续 4KB、8KB、16KB、…、4MB 内存空间的空闲链表,如下图所示:
通过 cat /proc/pagetypeinfo 命令可以看到当前系统中伙伴系统各个尺寸的可用连续内存块数量:
1
2
3
4
5
6
| Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
# 省略 ...
Node 0, zone DMA32, type Unmovable 91 124 85 1 57 23 22 10 4 7 7
Node 0, zone DMA32, type Movable 543 225 122 43 17 12 11 11 10 12 7
Node 0, zone DMA32, type Reclaimable 3 10 13 8 3 1 0 0 0 1 0
# 省略 ...
|
内核通过分配器函数 alloc_pages 到上面的多个链表中寻找可用连续页面:
1
| struct page * alloc_pages(gfp_t gfp_mask, unsigned int order)
|
假如要申请 8KB —— 连续两个页框的内存,工作流程如下所示。为了描述方便,先暂时忽略UNMOVEABLE、RELCLAIMABLE 等不同类型:
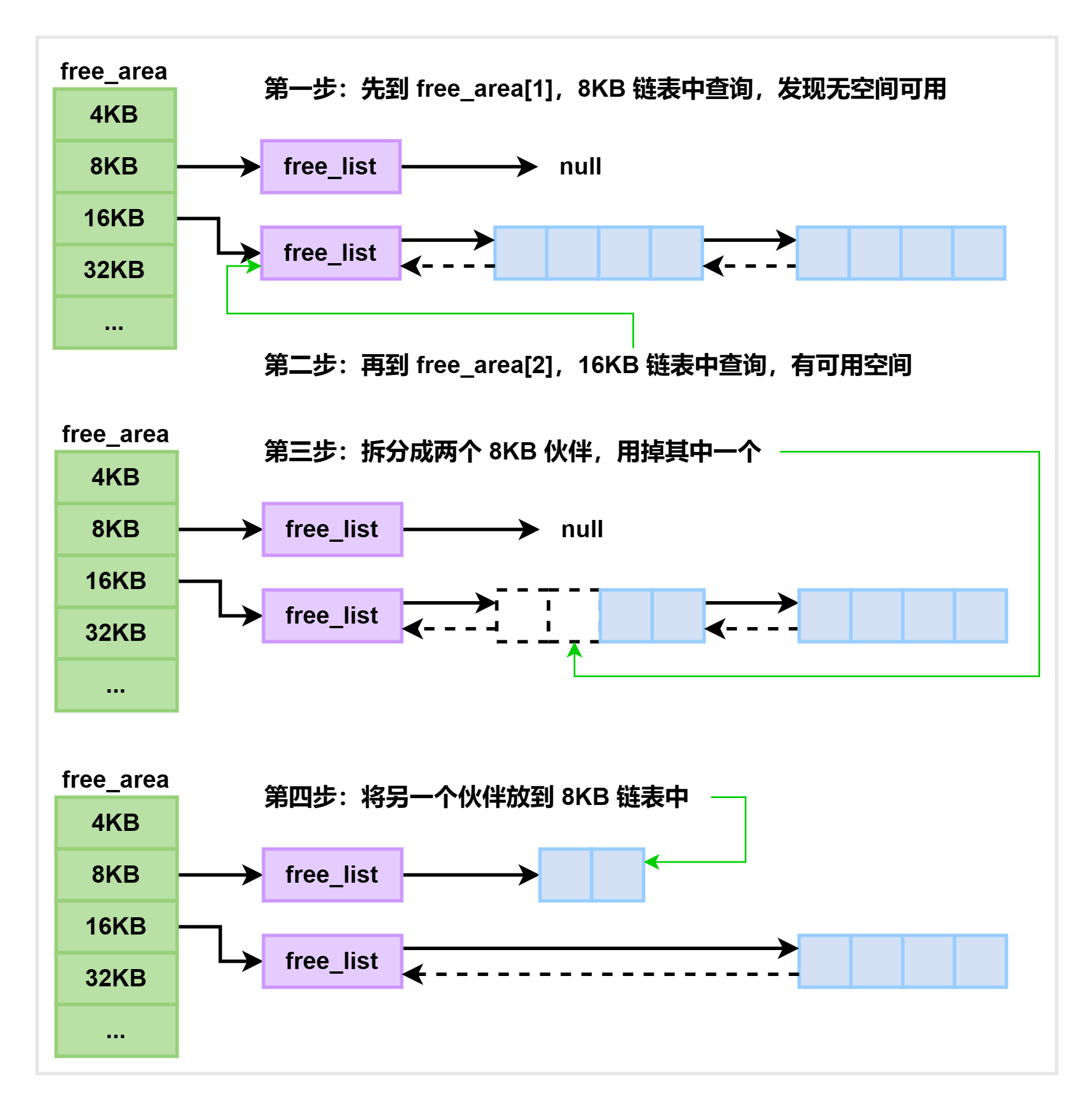
注释
伙伴系统中的伙伴指的是两个内存块,大小相同,地址连续,同属于一个大块区域。
在基于伙伴系统的内存分配中,有时需要将大块内存拆分成两个小伙伴。在释放内存时,可能会将两个小伙伴合并,以组成更大块的连续内存。
SLAB 分配器
上文中介绍的内存分配器都是以页 (Page) 为单位的,但实际上内核运行过程中使用的各个对象大小不尽相同,有的对象只有几十上百字节,直接使用伙伴系统来分配内存就会导致内存浪费。
为了解决这个问题,内核在伙伴系统的基础上,开发了一种专门用于内核的内存分配器,称为 slab 或 slub(两者都指同一种分配器)。
这个内存分配器最显著的特点是:它在一个 slab 中只分配特定大小、或者特定类型的对象。如下图所示:
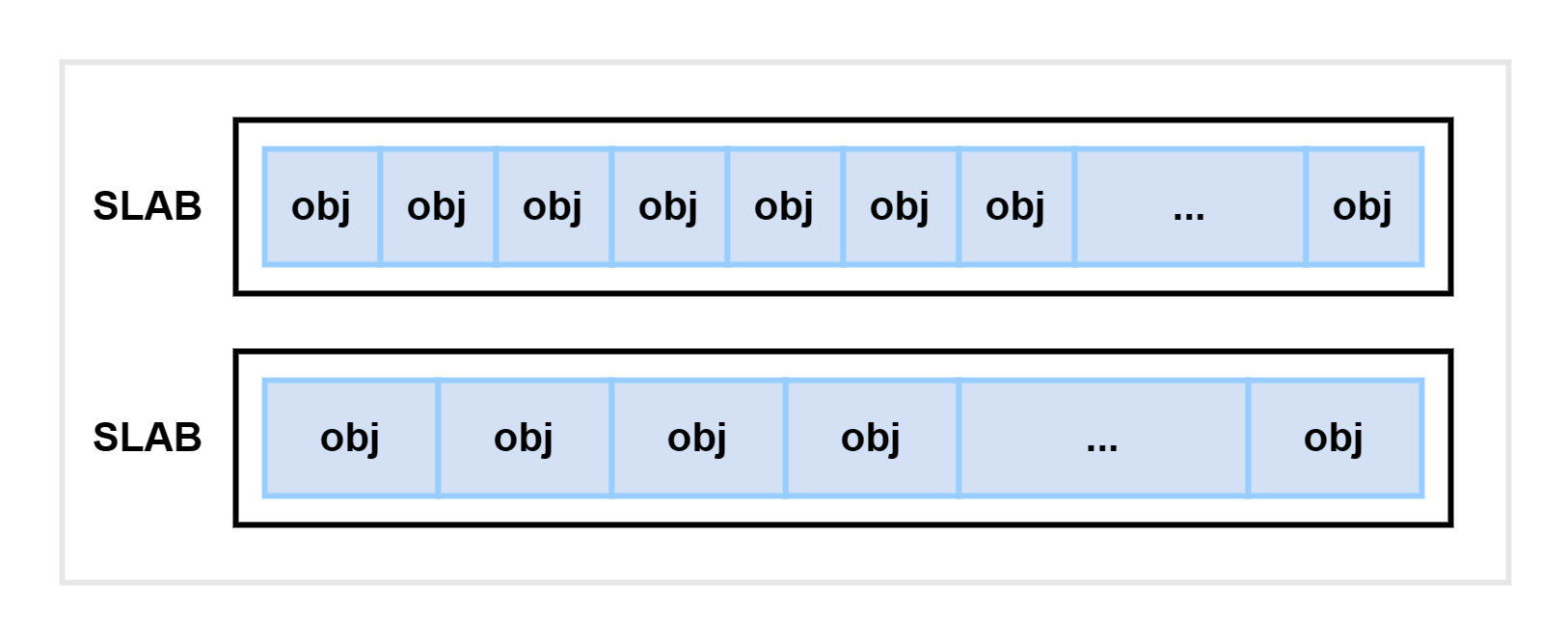
当一个对象释放内存后,同类的另一个对象可以直接使用这块内存。这种方法可以大大降低内存碎片发生的概率。
Slab 相关的内核对象定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
| //file: include/linux/slab_def.h
struct kmem_cache {
struct kmem_cache_node **node;
...
}
//file: mm/slab.h
struct kmem_cache_node {
struct list_head slabs_partial;
struct list_head slabs_full;
struct list_head slabs_free;
...
}
|
每个 cache 都有满 (slabs_full)、半满 (slabs_partial)、空 (slabs_free) 三个链表。每个链表节点都对应一个 slab,一个 slab 由个或者多个内存页组成。
每一个 slab 内都保存的是同等大小的对象。一个 cache 的组成如下图示:
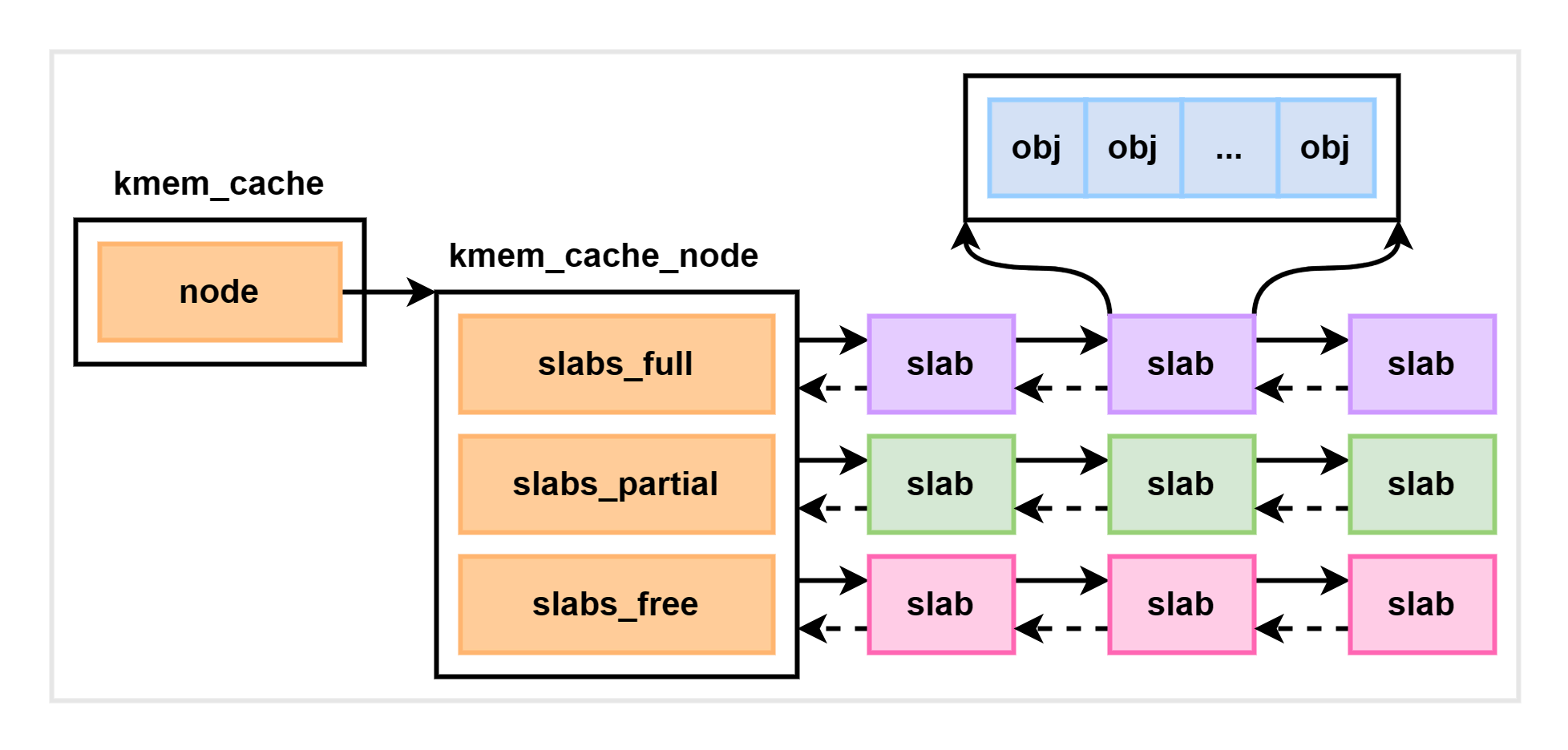
当缓存中的内存不足时,会调用基于伙伴系统的分配器(alloc_pages 函数)请求分配整页连续内存:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| //file: mm/slab.c
static void *kmem_getpages(struct kmem cache *cachep,
gfp_t flags, int nodeid)
{
...
flags |= cachep->alocflags;
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
flags |= __GFP_RECLAIMABLE;
page = alloc_pages_exact_node(nodeid, ...);
...
}
//file: include/linux/gfp.h
static inline struct page *alloc_pages_exact_node(int nid,
gfp_t gfp_mask, unsigned int order)
{
return __alloc_pages(gfp_mask, order, node_zonelist(nid, gfp_mask));
}
|
内核中会存在很多个 kmem_cache,它们在 Linux 初始化或者运行过程中被动态分配。这些中 cache 有些是专用的,有些是通用的。如下图所示:
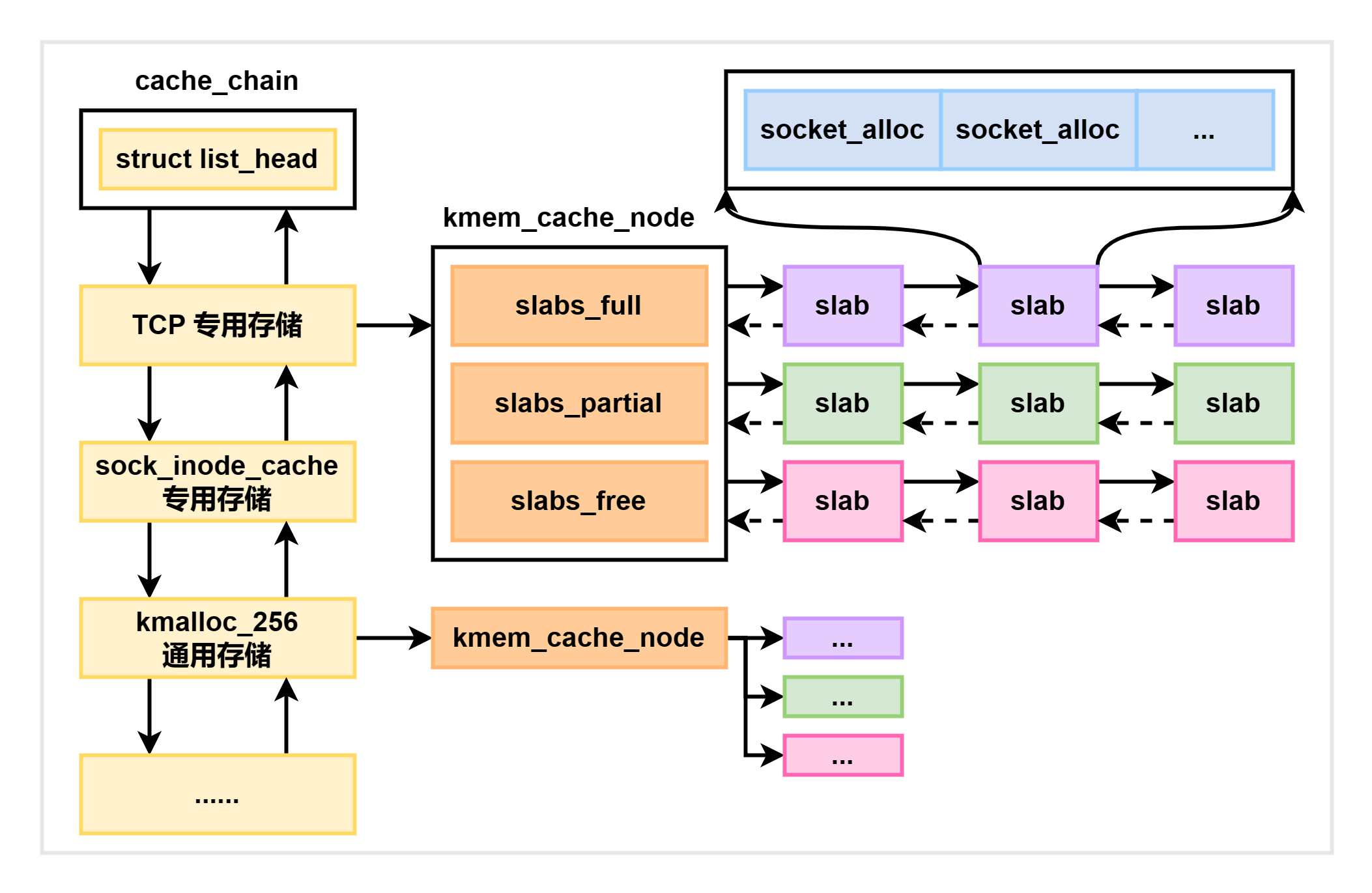
我们可以通过查看 /proc/slabinfo 来查看系统中所有的 kmem_cache:
1
2
3
4
5
6
7
8
9
10
| slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
...
kmalloc-512 2063 2064 512 16 2 : tunables 0 0 0 : slabdata 129 129 0
kmalloc-256 1512 1552 256 16 1 : tunables 0 0 0 : slabdata 97 97 0
kmalloc-192 2436 2436 192 21 1 : tunables 0 0 0 : slabdata 116 116 0
kmalloc-128 1372 1376 128 32 1 : tunables 0 0 0 : slabdata 43 43 0
kmalloc-96 1523 1932 96 42 1 : tunables 0 0 0 : slabdata 46 46 0
...
|
另外,Linux 还提供了一个特别方便的命令 slabtop 来按照占用内存从大到小进行排列,这个命令用来分析 slab 内存开销非常方便:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| # slabtop
Active / Total Objects (% used) : 221648 / 228379 (97.1%)
Active / Total Slabs (% used) : 7790 / 7790 (100.0%)
Active / Total Caches (% used) : 117 / 162 (72.2%)
Active / Total Size (% used) : 50400.97K / 51659.00K (97.6%)
Minimum / Average / Maximum Object : 0.01K / 0.23K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
36708 36613 99% 0.19K 1748 21 6992K dentry
35061 35054 99% 0.10K 899 39 3596K buffer_head
25152 25086 99% 0.12K 786 32 3144K kernfs_node_cache
21760 21657 99% 0.03K 170 128 680K lsm_inode_cache
15684 15684 100% 0.62K 1307 12 10456K inode_cache
7168 6751 94% 0.02K 28 256 112K kmalloc-16
5952 2985 50% 0.06K 93 64 372K vmap_area
4992 4898 98% 0.06K 78 64 312K kmalloc-64
4784 4737 99% 0.15K 184 26 736K vm_area_struct
4675 4675 100% 0.05K 55 85 220K ftrace_event_field
4608 4589 99% 0.01K 9 512 36K kmalloc-8
4608 4516 98% 0.03K 36 128 144K kmalloc-32
4186 4156 99% 0.57K 299 14 2392K radix_tree_node
3978 3956 99% 0.04K 39 102 156K ext4_extent_status
3776 3387 89% 0.06K 59 64 236K anon_vma_chain
...
|
无论是 /proc/slabinfo 还是 slabtop 命令的输出,都包含了每个 cache 中 slab 的两个关键信息:
- objsize:每个对象的大小;
- objperslab:一个 slab 里存放的对象数量。
/proc/slabinfo 还输出了一个 pagesperslab,表示一个 slab 占用的页面数量,每个页面大小为 4KB。这样就可以计算出每个 slab 占用的内存大小了。
最后,slab 管理器组件提供了若干接口函数,方便自己使用。以下是三个例子:
- kmem_cache_create:创建一个基于 slab 的内核管理对象管理器;
- kmem_cache_alloc:为某个对象申请内存;
- kmem_cache_free:将对象占用的内存归还给 slab 分配器。
总结
前文介绍的四个步骤中,前三个步骤属于基础模块,在用户态程序中也能使用,但第四步 slab 管理器只有内核支持。
注释
用户态程序无法直接使用内核的 slab 管理器来进行内存分配,但是可以使用一些第三方库,例如 jemalloc 等来实现类似的内存分配和管理机制。
虽然采用了 slab 分配机制极大地减少了内存碎片的发生,但是仍然不能完全避免内存碎片的产生。举个例子:
1
2
| # cat /proc/slabinfo | grep TCP
TCP 101 140 2304 14 8 ...
|
可以看出,对于 TCP cache 来说,每个 slab 占用了 8 个页面,也就是 8 x 4096 字节 = 32,768 字节。而每个 TCP cache 对象的大小为 2,304 字节,每个 slab 最多能存放 14 个该类对象,因此会有 512 字节的剩余空间。
虽然存在一些空间碎片,但是比起 slab 机制带来的性能提升,这点牺牲还是可以接受的。