XXL-JOB 是由许雪里大佬开源的一款分布式任务调度平台。其凭借着简单易操作的特性,赢得了许多小型自研公司的青睐,甚至像阿里这样的大型企业也将 XXL-JOB 集成到了自己的 ScheduleX 中。然而,这么优秀的一款开源软件,我竟然一直没有了解过。因此,趁着最近有空,我决定深入学习一下 XXL-JOB 的核心内容,遂著此文。
基础组件
XXL-JOB 主要包括调度中心和执行器两大基础组件。
调度中心
调度中心是一个单独的 Web 服务,位于源码中的 xxl-job-admin 模块。它主要用于触发定时任务,而且还提供了一个简易的后台管理页面,方便用户去管理定时任务。
调度中心依赖数据库,且支持横向扩展。然而,每个调度中心的节点必须连接到同一数据库,因此,即使数据库启用了主从复制,节点仍然需要指向主库。
调度中心的节点是无状态的,且它们之间不进行任何通信,数据仅通过唯一的数据库进行同步。
执行器
执行器是一个嵌入式 HTTP 服务,位于源码中的 xxl-job-core 模块,通常由第三方工程引用该模块,并在其内部配置执行器。该执行器通过 Netty 框架监听来自调度中心的命令,并执行相应的操作。
开发示例
搭建调度中心
首先,下载 XXL-JOB 的源码:
https://github.com/xuxueli/xxl-job.git
然后,部署一个 MySQL Server,并执行源码工程里 doc/db/tables_xxl_job.sql 内的 SQL,完成数据库的初始化:

最后,修改 src/main/resources/application.properties 中的数据源配置,并启动调度中心:
1
2
3
4
5
6
7
| ### xxl-job, datasource
spring.datasource.url=jdbc:mysql://xxx.xxx.com:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
# 修改用户名、密码
spring.datasource.username=yourusername
spring.datasource.password=yourpassword
# mysql 驱动
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
|
警告
如果 MySQL Server 部署在 VPS 导致连接超时,还需要修改连接池的配置,增大超时时间。
调度中心启动后,就可以登录控制台了,默认的 URL 为 http://{ipaddr}:8080/xxl-job-admin/toLogin,默认的账号密码为 admin & 123456:
创建执行器与任务
首先,在 SpringBoot 工程的 pom.xml 中引入 xxl-job-core 模块:
1
2
3
4
5
| <dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.4.1-SNAPSHOT</version>
</dependency>
|
然后,在配置类中注册一个 XxlJobSpringExecutor 执行器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| @Configuration
public class XxlJobConfiguration {
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
// 设置调用中心的连接地址
xxlJobSpringExecutor.setAdminAddresses("http://{ipaddr}:8080/xxl-job-admin");
// 设置执行器的名称
xxlJobSpringExecutor.setAppname("my-xxljob-executor-demo");
// 设置执行器的通信端口
xxlJobSpringExecutor.setPort(9999);
// 设置安全访问 token
xxlJobSpringExecutor.setAccessToken("default_token");
// 任务执行日志存放的目录
xxlJobSpringExecutor.setLogPath("/data/applogs/xxl-job/jobhandler");
return xxlJobSpringExecutor;
}
}
|
最后,创建一个 Bean 模式的任务,并启动 SpringBootApplication:
1
2
3
4
5
6
7
8
9
| @Component
public class TestJob {
private static final Logger logger = LoggerFactory.getLogger(TestJob.class);
@XxlJob("TestJob")
public void testJob() {
logger.info("TestJob 任务成功");
}
}
|
@XxlJob 注解:指定任务的 Bean,参数为任务的 BeanName,下文配置 JobHeadler 时需要这个参数。
完成以上步骤后,接下来我们只需要在 XXL-JOB-ADMIN 控制台配置刚刚创建的执行器与任务,就可以执行任务了。
在控制台配置执行器与任务
首先,点击执行器管理,注册上述配置的执行器:
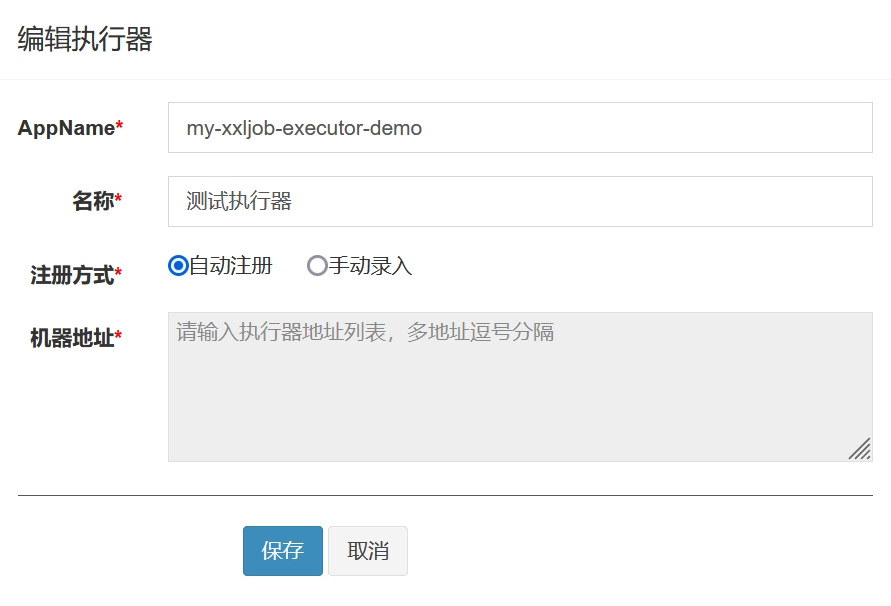
AppName 必须设置为 xxlJobSpringExecutor.setAppname() 中设置的英文名;- 名称 表示中文别名,可随意设置。
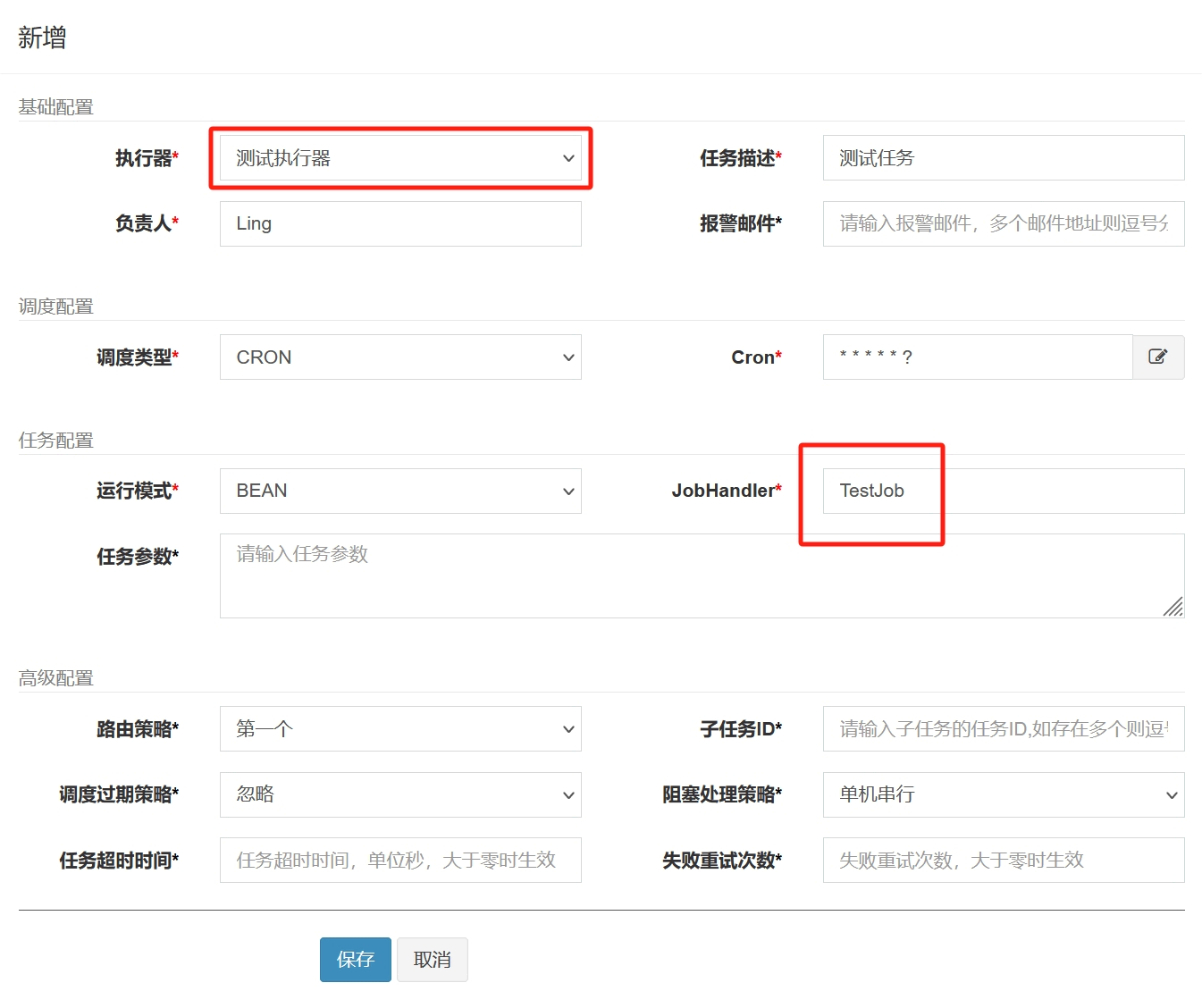
然后,点击任务管理,注册上述配置的 TestJob 任务,运行模式为 Bean:
最后,点击操作按钮,启动定时任务,便可在调度日志一栏查看执行结果:
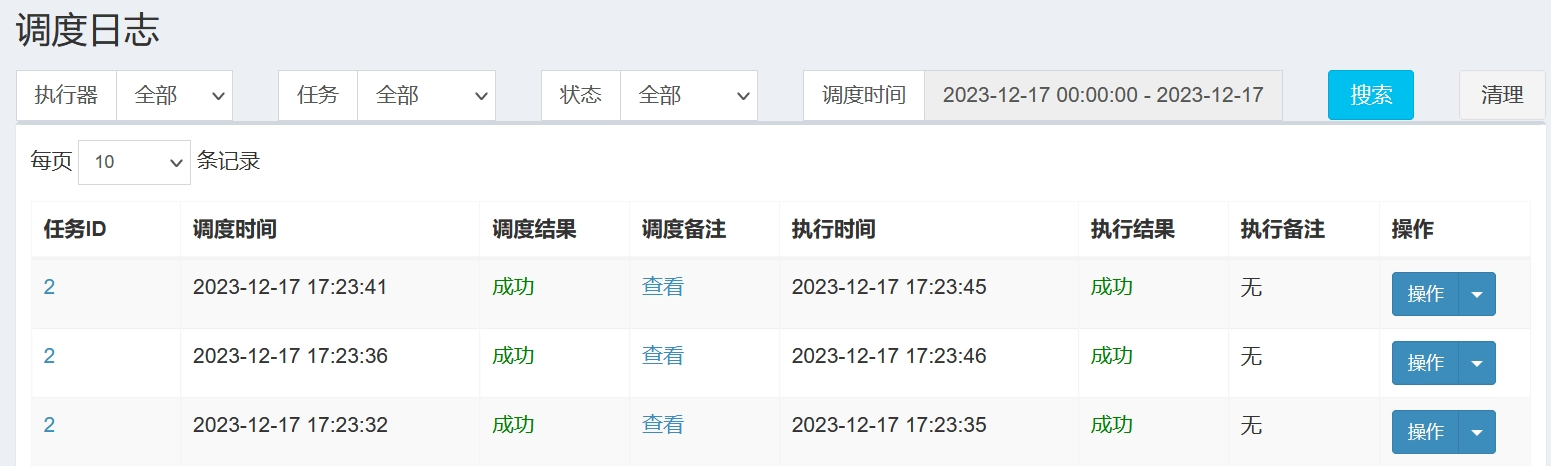
可见,XXL-JOB 成功运行了我们的定时任务。不过在上文中,我们设置的 CRON 表达式为每秒执行一次,而图中所示的每次执行的时间间隔并不准确,下文我们会详细分析其中的原因。
执行器的核心原理
执行器的启动过程
执行器的核心是 XxlJobExecutor,XXL-JOB 默认提供了两个执行器实现:XxlJobSimpleExecutor 和 XxlJobSpringExecutor。这里我们只学习最常用的 XxlJobSpringExecutor,也就是上文我们在 Demo 的配置类中注册的那个 Bean。
该类实现了 SmartInitializingSingleton 接口,所以在 Bean 实例化完成后会调用其 afterSingletonsInstantiated() 方法,初始化并启动执行器:
1
2
3
4
5
6
7
8
9
| @Override
public void afterSingletonsInstantiated() {
...
try {
super.start();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
|
该方法会执行父类 XxlJobExecutor 中的 start():
1
2
3
4
5
6
| public void start() throws Exception {
// 日志、回调线程初始化
...
// 初始化内嵌执行器
initEmbedServer(address, ip, port, appname, accessToken);
}
|
XxlJobExecutor.start() 的核心是 initEmbedServer() 方法,该方法会利用 Netty 框架启动一个 HTTP Server,并将自己注册到调度中心。核心实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| public void start(final String address, final int port, final String appname, final String accessToken) {
// [1] 创建执行器
executorBiz = new ExecutorBizImpl();
// [2] 通过子线程启动内嵌服务
thread = new Thread(new Runnable() {
@Override
public void run() {
// [4] 创建 Netty 的主从 Reactor 线程,以及用于执行任务的线程池
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
ThreadPoolExecutor bizThreadPool = new ThreadPoolExecutor(...);
try {
// [5] 启动内嵌服务
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
...// 添加 childHandler EmbedHttpServerHandler
// [6] bind
ChannelFuture future = bootstrap.bind(port).sync();
// [7] 将当前执行器注册到调度中心(向每个 admin 都发送 post 请求)
startRegistry(appname, address);
// [8] 阻塞直到服务结束
future.channel().closeFuture().sync();
} catch ...
}
});
// [3] 子线程以守护模式启动,开始执行内嵌服务启动流程
thread.setDaemon(true);
thread.start();
}
|
执行器启动后,便可接收来自调度中心的 HTTP 请求。当执行器收到来自调度中心的指令时,会把请求交给 ExecutorBiz 处理。ExecutorBiz 定义了执行器支持的所有方法:
1
2
3
4
5
6
7
8
9
10
11
12
| public interface ExecutorBiz {
// 发送心跳
public ReturnT<String> beat();
// 发送空闲心跳
public ReturnT<String> idleBeat(IdleBeatParam idleBeatParam);
// 启动一个任务
public ReturnT<String> run(TriggerParam triggerParam);
// 终止一个任务
public ReturnT<String> kill(KillParam killParam);
// 获取执行器 log
public ReturnT<LogResult> log(LogParam logParam);
}
|
ExecutorBiz 有两个实现类,分别是 ExecutorBizImpl 和 ExecutorBizClient。其中:
ExecutorBizImpl 是由执行器使用,负责处理来自调度中心的请求;ExecutorBizClient 由调度中心使用,负责发送相应的命令。
任务的注册过程
定时任务的抽象类是 IJobHandler,XXL-JOB 提供了三个默认实现:
MethodJobHandler:用于执行 BEAN 模式创建的任务;GlueJobHandler:用于执行 GLUE 模式下的 Java 任务;ScriptJobHandler:用于执行除 GLUE(Java) 模式外的其它 GLUE 脚本任务,例如 GLUE(Shell)、GLUE(Python) 等。
本文我们只介绍 MethodJobHandler 的注册流程。XXL-JOB 提供了一个 @XxlJob 注解,执行器启动时会从 Spring 容器中寻找被该注解标记的 Bean,调用链路如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| XxlJobSpringExecutor#afterSingletonsInstantiated
|
+->// 扫描 Spring 容器中被 @XxlJob 标注的 Bean
XxlJobSpringExecutor#initJobHandlerMethodRepository
|
+->// 将这些 Bean 注册到 Map
XxlJobExecutor#registJobHandler(
com.xxl.job.core.handler.annotation.XxlJob,
java.lang.Object,
java.lang.reflect.Method)
|
+-> XxlJobExecutor#registJobHandler(
java.lang.String,
com.xxl.job.core.handler.IJobHandler)
|
XxlJobExecutor 内部维护了一个 map 容器 jobHandlerRepository,initJobHandlerMethodRepository() 中扫描到的 Bean 最终会由 registJobHandler() 封装成一个 MethodJobHandler 对象,并注册到该容器中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| // 定时任务容器
private static ConcurrentMap<String, IJobHandler> jobHandlerRepository
= new ConcurrentHashMap<String, IJobHandler>();
// 注册定时任务到容器
public static IJobHandler registJobHandler(String name, IJobHandler jobHandler){
...
return jobHandlerRepository.put(name, jobHandler);
}
protected void registJobHandler(XxlJob xxlJob, Object bean, Method executeMethod){
...
// registry jobhandler
registJobHandler(name,
new MethodJobHandler(bean, executeMethod, initMethod, destroyMethod));
}
|
任务的执行过程
上文我们讲过,执行器启动内嵌服务时,向 Channel 注册了一个 EmbedHttpServerHandler,它是 io.netty.channel.SimpleChannelInboundHandler 的实现类,当有数据可读时会调用其 channelRead0 方法。EmbedHttpServerHandler#channelRead0() 会解析来自调度中心的请求,并交给线程池处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| @Override
protected void channelRead0(final ChannelHandlerContext ctx, FullHttpRequest msg) throws Exception {
// [1] 解析调度中心的指令
String requestData = msg.content().toString(CharsetUtil.UTF_8);
String uri = msg.uri(); // restfull,url 就是指令类型,例如 run、beat...
HttpMethod httpMethod = msg.method();
boolean keepAlive = HttpUtil.isKeepAlive(msg);
String accessTokenReq = msg.headers().get(XxlJobRemotingUtil.XXL_JOB_ACCESS_TOKEN);
// [2] 交给线程池处理命令
bizThreadPool.execute(new Runnable() {
@Override
public void run() {
// [3] 执行命令
Object responseObj = process(httpMethod, uri, requestData, accessTokenReq);
// [4] 返回响应
String responseJson = GsonTool.toJson(responseObj);
writeResponse(ctx, keepAlive, responseJson);
}
});
}
|
执行命令的核心是 process() 方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| private Object process(HttpMethod httpMethod, String uri, String requestData, String accessTokenReq) {
// 参数校验
...
// services mapping
try {
switch (uri) {
case "/beat":
...
case "/idleBeat":
...
case "/run":
TriggerParam triggerParam = GsonTool.fromJson(requestData, TriggerParam.class);
return executorBiz.run(triggerParam);
case "/kill":
...
case "/log":
...
default:
...
}
} catch ...
}
|
process() 通过请求的 url 来区分命令类型,进而调用 ExecutorBiz 实现类中的方法处理命令。以运行任务的 run 命令为例,该方法的实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| @Override
public ReturnT<String> run(TriggerParam triggerParam) {
// [1] 从缓存 jobThreadRepository 中取出 jobThread,第一次调用时为 null
JobThread jobThread = XxlJobExecutor.loadJobThread(triggerParam.getJobId());
// 从 jobThread 中取出 jobHandler
IJobHandler jobHandler = jobThread!=null?jobThread.getHandler():null;
String removeOldReason = null;
// [2] 获取任务类型
GlueTypeEnum glueTypeEnum = GlueTypeEnum.match(triggerParam.getGlueType());
if (GlueTypeEnum.BEAN == glueTypeEnum) {
// [3] 根据 BEAN Name 取出上文注册在 jobHandlerRepository 中的 Handler
IJobHandler newJobHandler = XxlJobExecutor.loadJobHandler(triggerParam.getExecutorHandler());
// [4] 如果 jobThreadRepository 缓存过期
if (jobThread!=null && jobHandler != newJobHandler) {
...
jobThread = null;
jobHandler = null;
}
// [5] 如果 jobHandler 为空,缓存新获取到的 jobHandler
if (jobHandler == null) {
jobHandler = newJobHandler;
if (jobHandler == null) {
return ...
}
}
} else if ...
// [6] 执行拒绝策略
if (jobThread != null) {
...
}
// [7] 创建一个封装了 jobHandler 的 JobThread,注册到缓存
if (jobThread == null) {
jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(), jobHandler, removeOldReason);
}
// [8] 将参数添加到 Trigger 队列,等待异步执行
ReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);
return pushResult;
}
|
[1]:进入该方法时,首先尝试从缓存 jobThreadRepository 中获取 jobThread,如果 jobHandler 不为 null,再从中取出 jobHandler;[2]:根据任务类型处理对应的指令,这里我们重点介绍 BEAN 类型任务:[3]:根据调度中心配置的 BEAN Name 获取 上文 注册到缓存 jobHandlerRepository 中的 jobHandler;[4]:如果缓存 jobThreadRepository 中存在 jobThread,但其内部的 jobHandler 与 jobHandlerRepository 中的不一致,则清空 jobThread 和 jobHandler 的引用;说明:为什么要清空 jobThreadRepository 中的缓存
jobHandlerRepository 中缓存了与 Bean Name 对应的 JobHandler,这个对应关系是永远不变的;jobThreadRepository 中缓存了与任务 ID 对应的 JobThread,而 JobThread 中又封装了 JobHandler,可以通过控制台动态修改任务 ID 对应的 JobHandler。
因此 jobThreadRepository 中缓存的 JobThread 有可能失效,所以这里需要更新缓存。
[5]:如果 jobHandler 为 null,则将 jobHandlerRepository 中的 newJobHandler 赋值给 jobHandler;
[6]:根据用户配置,执行拒绝策略;[7]:如果 jobThread 为 null,表明是第一次执行该任务,或者在第四步清空过 jobThread,所以这里创建一个新的 jobThread 并注册到 jobThreadRepository;[8]:将参数添加到阻塞队列 triggerQueue,然后直接返回。
由于定时任务的执行可能十分耗时,而执行器作为一个 HTTP Server,不适合长时间阻塞(否则会触发超时)。所以上述代码在第 8 步将参数添加到阻塞队列后就直接返回了,JobThread 在自己的循环中再不断拉取阻塞队列中的任务进行处理:
1
2
3
4
5
6
7
8
9
| // com.xxl.job.core.thread.JobThread#run
...
while(!toStop){
triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);
...
handler.execute(); // 执行任务
...
}
...
|
执行器收到触发指令后会直接返回 HTTP 响应,具体的任务是异步处理的,当任务执行完毕后,还需要发送回调请求将执行结果上报调度中心,这个过程也是异步的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // com.xxl.job.core.thread.JobThread#run
...
finally {
...
// 回调,发送任务执行结果
TriggerCallbackThread.pushCallBack(new HandleCallbackParam(
triggerParam.getLogId(),
triggerParam.getLogDateTime(),
XxlJobContext.getXxlJobContext().getHandleCode(),
XxlJobContext.getXxlJobContext().getHandleMsg() )
);
...
}
...
|
了解了执行器的核心内容后,接下来我们分析 XXL-JOB 的重中之重:调度中心。
调度服务的核心原理
任务调度线程
调度中心会在 XxlJobAdminConfig 的后置处理器中启动一个调度线程,该线程会每秒查询一次 xxl_job_info 表内 nowTime + PRE_READ_MS 之前的待处理任务,最多 preReadCount 个:
1
2
3
4
5
6
7
8
| // 调度中心支持集群部署,所以每个节点在处理前要通过锁表抢占资源
preparedStatement = conn.prepareStatement(
"select * from xxl_job_lock where lock_name = 'schedule_lock' for update" );
preparedStatement.execute();
// 查询 nowTime + PRE_READ_MS 之前的待触发任务,最多 preReadCount 个
List<XxlJobInfo> scheduleList = XxlJobAdminConfig
.getAdminConfig().getXxlJobInfoDao()
.scheduleJobQuery(nowTime + PRE_READ_MS, preReadCount);
|
xxl_job_lock:调度中心支持集群部署,每个节点在处理前通过锁表抢占资源;nowTime + PRE_READ_MS:未来 5s 的时间窗口;preReadCount:每次最多查询任务数,计算方法: treadpool-size * trigger-qps (each trigger cost 50ms, qps = 1000/50 = 20)。
拿到待处理的任务列表后,调度线程会将这些任务根据触发时间划分为三个部分:
- 任务过期时间已经超过 5s;
- 任务已经过时,但是过时时间不足 5s;
- 任务未超时,且下次触发时间在未来 5s 内。
上文答疑:为什么执行间隔并不精确?
调度线程理论上每 1000 毫秒轮训一次,但实际上做不到毫秒级精确度:
1
2
3
4
5
6
7
8
9
10
11
| // Wait seconds, align second
if (cost < 1000) { // scan-overtime, not wait
try {
// pre-read period: success > scan each second; fail > skip this period;
TimeUnit.MILLISECONDS.sleep((preReadSuc?1000:PRE_READ_MS) - System.currentTimeMillis()%1000);
} catch (InterruptedException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
}
|
原因有以下几个:
- 如果当次任务执行时间超过了 1s,那么下次轮训自然而然会被推迟;
- 即便当次任务在 1s 内执行完毕,
TimeUnit.MILLISECONDS.sleep 也无法准确的让线程休眠指定毫秒,因为该方法内部还是调用的 Thread.sleep。
过期时间超过 5s 的任务
对于第一部分过期时间超过 5s 的任务,会根据任务配置的调度过期策略来选择要不要触发:
1
2
3
4
5
6
7
8
9
10
| if (nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS) {
// 1、获取任务过期策略
MisfireStrategyEnum misfireStrategyEnum = MisfireStrategyEnum.match(jobInfo.getMisfireStrategy(), MisfireStrategyEnum.DO_NOTHING);
if (MisfireStrategyEnum.FIRE_ONCE_NOW == misfireStrategyEnum) {
// 如果是 FIRE_ONCE_NOW,立即触发一次
JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.MISFIRE, -1, null, null, null);
}
// 2、更新该任务的下次触发时间
refreshNextValidTime(jobInfo, new Date());
}
|
这两个策略就是字面意思:
- 直接忽略这个过期的任务;
- 立马触发一次这个过期任务。
过期时间小于 5s 的任务
对于第二部分过期时间小于 5s 的任务,会立马触发一次。如果判断下一次触发时间就在 5s 内,就将这个任务放到一个时间轮里,等待下一次触发执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| else if (nowTime > jobInfo.getTriggerNextTime()) {
// 1. 立马触发一次任务,并更新下次触发时间
JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.CRON, -1, null, null, null);
refreshNextValidTime(jobInfo, new Date());
// 2. 如果下次触发时间在未来五秒内,则将任务放到时间轮
if (jobInfo.getTriggerStatus()==1 && nowTime + PRE_READ_MS > jobInfo.getTriggerNextTime()) {
// 1、make ring second
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
// 2、push time ring
pushTimeRing(ringSecond, jobInfo.getId());
// 3、fresh next
refreshNextValidTime(jobInfo, new Date(jobInfo.getTriggerNextTime()));
}
}
|
未到触发时间的任务
对于第三部分任务,由于还没到触发时间,所以直接放到时间轮里等待处理。
到此,一次调度的计算就完成了。
时间轮的原理与实现
时间轮 (Time Ring) 是一种用于处理时间相关事件的数据结构,它会将时间划分为一系列的时间槽 (slots),每个时间槽代表一段时间间隔,例如毫秒或秒。时间轮上有多个槽,它们形成一个环形结构,类似于钟表的刻度。
在具体的实现中,时间轮是一种线程安全的 HashMap,其中键 (Key) 表示时间刻度,而值 (Value) 则表示待执行的任务 ID 列表:
1
2
3
| private volatile static
Map<Integer, List<Integer>> ringData
= new ConcurrentHashMap<>();
|
示意图如下:
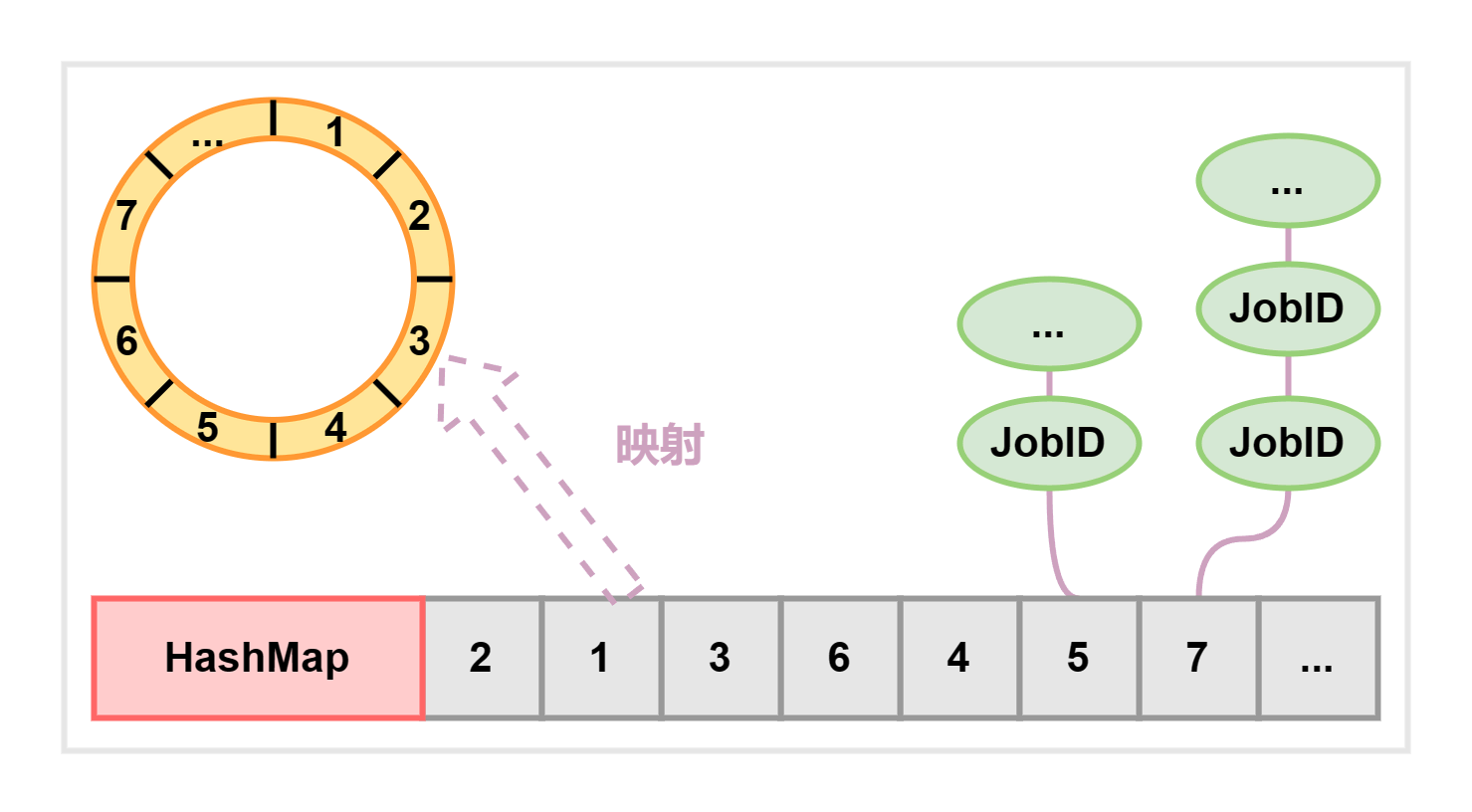
当调度线程将待执行任务放置到其下次触发时间所在的刻度上时,时间轮处理线程 ringThread 即可开始消费这些任务:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| while(...) {
// 执行频率控制...
try {
// 获取触发刻度内的任务
List<Integer> ringItemData = new ArrayList<>();
// 获取当前在分钟内的秒数,[0 - 59]
int nowSecond = Calendar.getInstance().get(Calendar.SECOND); // 避免处理耗时太长,跨过刻度,向前校验一个刻度;
for (int i = 0; i < 2; i++) {
List<Integer> tmpData = ringData.remove( (nowSecond+60-i)%60 );
if (tmpData != null) {
ringItemData.addAll(tmpData);
}
}
// 触发到期任务的执行
logger.debug(">>>>>>>>>>> xxl-job, time-ring beat : " + nowSecond + " = " + Arrays.asList(ringItemData) );
if (ringItemData.size() > 0) {
// do trigger
for (int jobId: ringItemData) {
// do trigger
JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1, null, null, null);
}
// clear
ringItemData.clear();
}
} catch ...
}
|
该时间轮一共划分了 60 个刻度,分别对应一分钟内的 60 秒。每次处理时,都会将当前秒跟前一秒这两个刻度的任务取下来处理。之所以要往前取一个刻度,是为了避免上次处理耗时超过了 1s,导致任务被遗漏。
注意
与调度线程一样,时间轮处理线程也是尽可能每 1000 毫秒执行一次,并不保证毫秒级精度:
1
2
3
4
5
6
7
8
9
10
11
12
| while(...) {
// align second
try {
TimeUnit.MILLISECONDS.sleep(1000 - System.currentTimeMillis() % 1000);
} catch (InterruptedException e) {
if (!ringThreadToStop) {
logger.error(e.getMessage(), e);
}
}
// 处理任务...
}
|
任务触发过程
无论是立即触发任务,还是交由时间轮去触发,最终都是由 JobTriggerPoolHelper 处理的。JobTriggerPoolHelper 是任务的异步触发器,它内部维护了一快一慢两个线程池:
1
2
| private ThreadPoolExecutor fastTriggerPool = null;
private ThreadPoolExecutor slowTriggerPool = null;
|
JobTriggerPoolHelper 默认情况下会将任务交给 fastTriggerPool 处理,同时记录任务的慢触发次数(触发时间超过 500ms):
这个耗时指的是执行器收到触发命令,并返回 HTTP 结果的耗时。因为执行器也是异步的,所以这个时间不包括任务的实际运行时间。
1
2
3
4
5
6
7
8
9
10
11
12
| /*
com.xxl.job.admin.core.thread.JobTriggerPoolHelper#addTrigger
--> java.util.concurrent.ThreadPoolExecutor#execute
--> java.lang.Runnable#run
*/
long cost = System.currentTimeMillis()-start;
if (cost > 500) { // ob-timeout threshold 500ms
AtomicInteger timeoutCount = jobTimeoutCountMap.putIfAbsent(jobId, new AtomicInteger(1));
if (timeoutCount != null) {
timeoutCount.incrementAndGet();
}
}
|
如果该任务一分钟内慢触发次数超过 10 次,就将这次触发任务交给 slowTriggerPool 处理:
1
2
3
4
5
6
| // com.xxl.job.admin.core.thread.JobTriggerPoolHelper#addTrigger
ThreadPoolExecutor triggerPool_ = fastTriggerPool;
AtomicInteger jobTimeoutCount = jobTimeoutCountMap.get(jobId);
if (jobTimeoutCount!=null && jobTimeoutCount.get() > 10) { // job-timeout 10 times in 1 min
triggerPool_ = slowTriggerPool;
}
|
快慢线程优化机制通过隔离操作,有效避免了慢任务阻塞其他任务的触发。
执行器的选择
JobTriggerPoolHelper 将待触发的任务提交给快慢线程池后,会由 XxlJobTrigger 完成任务的触发过程。由于执行器可能由多个实例,因此这里会通过路由策略选择执行器去执行:
至此,XXL-JOB 的核心内容就介绍完了。